



Künstliche Intelligenz, wie beispielsweise Chat GPT, ist heutzutage in aller Munde und löst eine Vielzahl unterschiedlichster Reaktionen aus. In einer Blogserie wollen wir Themen aus dem Bereich der künstlichen Intelligenz etwas näher beleuchten.
Was bisher geschah:
Im ersten Teil meiner Blogserie habe ich eine Einführung in KI gegeben und die grundlegenden Technologien zusammengestellt. Nun wollen wir uns auf das Thema Machine Learning fokussieren.
Kommen wir zum Kern des heutigen Blogs,
Machine Learning.
Machine Learning ist eine der wichtigsten Disziplinen im Bereich der künstlichen Intelligenz.
So können beispielsweise Werte in einer Datenbank so trainiert werden, dass es möglich wird künftige Werte vorauszusagen.
Nehmen wir bspw. einen Imbissstand, welcher verschiedene Pizzas verkauft. Mithilfe der Verkaufszahlen über die letzten 2 Jahre, sowie zusätzlichen Daten wie dem Wetter am Verkaufstag oder den Ferienregelungen am Verkaufsort können wir ein Modell erstellen, welches voraussagen kann, wie viele Pizzas von welchem Typ an einem bestimmten Datum in der Zukunft verkauft werden. Selbstverständlich ist diese Voraussage nicht absolut korrekt, sondern eine statistische Wahrscheinlichkeit.
Doch wie geschieht ein solches Training?
Automatisiertes Machine Learning
In Azure kann ein Training eines Datensets automatisch mit dem Auto ML Feature von Azure Machine Learning erfolgen, oder manuell mittels Konfiguration innerhalb eines Designers.
Bei Auto ML stellen sie alle Werte (Values) in einem Excel zusammen und definieren den vorauszusehenden Wert, in unserem Fall die Verkaufszahlen. Ist dies gemacht, prüft Auto ML, mit welchem Modell es die qualitativ besten Voraussagen tätigen kann.
Dabei kann es auf eine Vielzahl von Modellen zurückgreifen und diese durchrechnen. Im genannten Beispiel bringt vermutlich der Algorithmus MaxAbsScaler, LightGBM das gute Resultat. Konkret werden mit MaxAbsScaler die Zielwerte geglättet und in einem Bereich von -1 bis +1 gebracht. Anschliessend wird mit dem LightGBM ein Modell erstellt, dass die Wahrscheinlichkeit bei Voraussagen definiert. Grob erklärt werden alle Werte in Entscheidungsbäume eingetragen und geschaut, welcher Zielwert dabei herausgekommen ist. Bei einem neuen Zielwert wird der Entscheidungsbaum laufend angepasst, so dass am Schluss ein fertiges Modell vorhanden ist, bei welchem man Werte eingeben kann und daraus den zu erwartenden Zielwert errechnen kann.
Im Rahmen des Trainings werden die Daten in zwei Teile unterteilt. Ein Trainigsset und Set, mit welchem die erstellten Modelle geprüft werden, ob die gemachten Voraussagen zutreffen.
AutoML von Azure führt die genannten Schritte mit ca. 35 Modellen durch und entscheidet am Schluss, welches Modell zur Verwendung kommt.
Ist das Modell erstellt, kann abgefragt werden, wie viele Pizza Napoli bei Regen in Bern an der Marktgasse verkauft werden, wenn nicht gerade Ferien sind und keine Demo stattfindet. Damit diese Abfrage mittels API Call gemacht werden kann, wird ein Deployment des vorher erstellen Modells gemacht und ein Endpoint (API), auf welchem die Zielwerte übergeben werden können, generiert.
Manuelle Machine Learning Modelle
Wie erwähnt, können Machine Learning Modelle auch manuell erstellt werden.
Der folgende Ablauf zeigt eine Lösung, welche anhand von Werten entscheiden soll, ob ein Patient Diabetes gefährdet ist oder nicht. Entgegen dem Auto Machine Learning Beispiel von vorhin werden die einzelnen Schritte manuell definiert. Auch das Modell für die Regression wird manuell definiert.
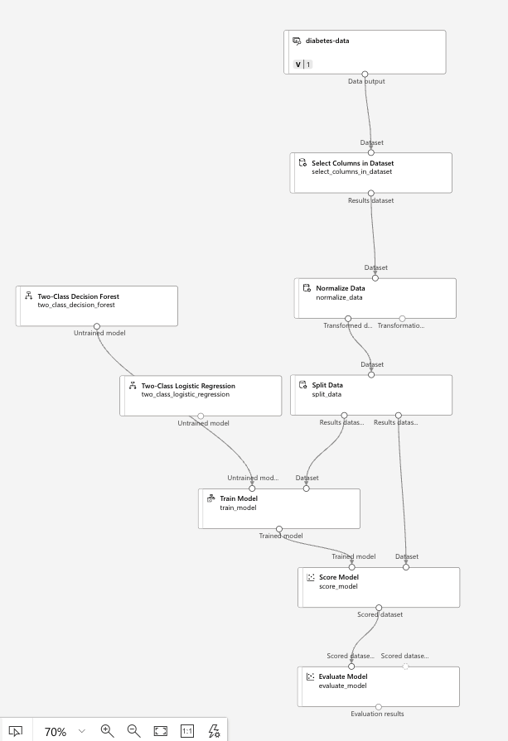
Die Daten im obigen Beispiel werden aus einem File geladen. Im ersten Schritt wird bestimmt, welche Daten für das Modell überhaupt relevant sind.
Nun werden die Daten "normalisiert", so dass die Werte aus der Quelle vergleichbarer werden. In der Regel werden die Werte in eine Grössenordnung zwischen 0 und 1 transferiert.
Als Nächstes werden die Daten in ein Trainigsset (Bsp. 80 % der Daten) und ein Validierungsset (Bsp. 20 % der Daten) unterteilt.
Mit dem "Two Class Decision Forest" wird das Modell trainiert. Die "Two Class" Klassifikation wurde gewählt, da wir nur wissen wollen, ob ein Patient Diabetes gefährdet ist oder nicht. In diesem Beispiel wollen wir keine einzelnen Werte prognostizieren.
Wurde das Modell auf der Basis des Trainigssets erstellt, wird dieses gegen das Trainigsset geprüft und zum Schluss evaluiert, ob die prognostizierten Werte mit den effektiven Werten im Trainigsset übereinstimmen resp. wie gross die Abweichung ist.
Wie gesagt bildet Machine Learning eine wichtige Basis aller heutigen KI Lösungen.
KI Jumpstart Angebot für Unternehmen
Gerne verweise ich an dieser Stelle auf unser Angebot, mit welchem wir ihnen KI Lösungen anhand einer konkreten Fragestellung bei Ihnen in Form eins Proof of Concept umsetzen.

Ich freue mich auf die Reise durch die Welt der künstlichen Intelligenz mit Ihnen und ich bin gespannt, ob wir die Intelligenz zusammen noch finden werden ;-)
