



Seit der Einführung von ChatGPT im November 2022 hört man in vielen Unternehmen den Ruf: «Ich will ChatGPT in meinem Unternehmen nutzen!». Die Idee ist, den Mitarbeitenden interne Dokumente und Informationen mithilfe künstlicher Intelligenz (KI) besser zugänglich und nutzbar zu machen, und das möglichst unkompliziert. Doch wie setzt man ein solches Vorhaben in der Praxis um? Mit dem richtigen Know-how ist es möglich, eine effektive Knowledge Management Lösung auf bestehenden Dokumenten zu realisieren. Erfahren Sie am Beispiel der Ausgleichskasse Basel-Stadt (AKBS), wie ein Azure Open AI in einem Pilotprojekt im Unternehmen nutzbar gemacht wurde.
Die AKBS, ein modernes Dienstleistungsunternehmen im Bereich der schweizerischen Sozialversicherungen, betrachtet das Wissen ihrer Mitarbeitenden als das wichtigste Gut. Die Herausforderung besteht darin, dieses Wissen schnell, einfach und verständlich für alle zugänglich zu machen. Roger Ammon, Leiter IT und Finanzen bei der AKBS, hat im Rahmen seiner Masterarbeit zum Thema Data Driven Organisation untersucht, wie das bestehende Wissen innerhalb der AKBS den Mitarbeitenden besser zugänglich gemacht werden kann.
Die drei grossen Wissensquellen der AKBS, welche integriert werden sollten, waren: das bestehende Wiki, die bestehenden Dokumente im Intranet (u.a. Weisungen und Richtlinien) sowie die Online-Hilfe der Fachanwendung.
Die AKBS hat sich entschieden, innerhalb eines Proof of Concept die neuesten Technologien der künstlichen Intelligenz, bei sich einem Härtetest zu unterziehen und zu prüfen, ob damit ein echter Mehrwert geschaffen werden kann, resp. ob all die hochtrabenden Versprechen, welche im Internet kursieren, auch erfüllt werden können.
Theorieteil: KI-Lösung auf lokalen Daten
Bevor wir zum Vorgehen und die konkrete Umsetzung kommen, wollen wir kurz erklären, wie eine KI-Lösung auf lokalen Daten aufgebaut ist:
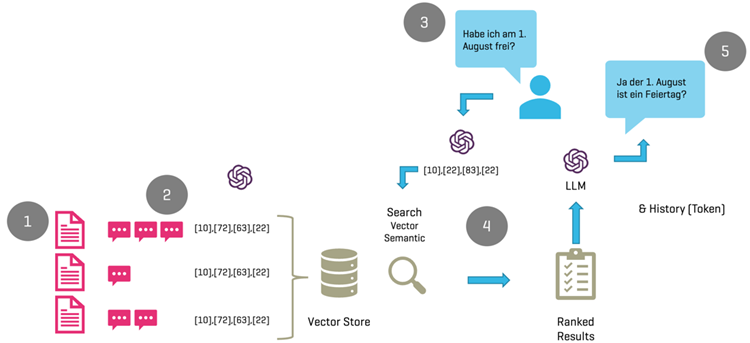
Der technische Ablauf umfasst die Verwendung einer kognitiven Suche, die Basisdokumente filtert und einem Large Language Model (Azure Open AI) zur Beantwortung übergibt.
Im Zentrum der Lösung steht eine kognitive Suche, welche anhand der Fragestellung die zu verwendenden Basisdokumente herausfiltert und diese einem Large Language Model (Azure Open AI) zur Beantwortung übergibt.
- In einem ersten Schritt werden die Basisdokumente (Bsp. PDFs) in einzelne Fragmente à 500 bis 1000 Zeichen unterteilt.
- Die Fragmente, welche in PDFs gespeichert wurden, werden mithilfe eines entsprechenden LLM Modells in Vektoren umgewandelt. In unserem Falle haben wir das Modell «text-embedding-ada-002» von Open AI verwendet. Die Vektoren resp. Embeddings werden anschliessend in einer Vektordatenbank abgelegt. In der vorliegenden Architektur haben wir Azure Cognitive Search, für das Speichern der Vektoren verwendet.
- Die Frage des Benutzers wird in Freitextform innerhalb eines Bots auf einer Webseite erfasst. Die Frage «Habe ich am 1. August frei?» wird ebenfalls mit dem «text-embedding-ada-002» Modell in einen Vektor umgerechnet und in der folgenden Vektorsuche weiterverwendet.
- Mit dem soeben erstellen Vektor, werden die Vektoren innerhalb der Vektordatenbank durchsucht (Azure Cognitive Search). Dabei werden die 3-5 besten Resultate resp. die passendsten PDFs gefunden und an das Large Language Modell (Azure Open AI) zusammen mit der Frage und dem Prompt, welche u.a. beschreibt, was die Aufgabe des Bots ist, zur Beantwortung übergeben.
- Azure OpenAI übernimmt die Beantwortung der Frage und gibt das Resultat aus. In unserem Beispiel wurde basierend auf dem Mitarbeiterhandbuch die Frage mit «Ja» beantwortet. Der gesamte Verlauf der Frage bis hin zur Beantwortung, wird bei einer Folgefrage wiederum an das LLM übergeben, wodurch es möglich ist, kontextbasierte Folgefragen zu stellen.
Der Praxistext von ChatGPT auf internen Daten
Learn to Fail – Fail to Learn
Der erste Prototyp, bei welchem die zur Verfügung gestellten Dokumente 1:1 in die Lösung integriert wurden, zeigte jedoch, dass die Antworten des Bots qualitativ eher schlecht waren. Auch stellte sich heraus, dass viel implizites Wissen bei den Mitarbeitern vorhanden war, was zu unpräzisen Fragen und falschen Dokumenten für die Befragung führte. Dieses Resultat war relativ ernüchternd. In Zusammenarbeit mit GARAIO wurden verschiedene Massnahmen ergriffen, um diese Herausforderungen zu überwinden.
Don’t give up: Zweite Iteration zeigt Erfolg
Im Rahmen einer zweiten Iteration wurde die Lösung wie folgt optimiert:
- Die Unterteilung der Originaldateien haben wir so angepasst, dass in den einzelnen Teilen weniger Zeichen vorhanden sind und so die Suche präzisere Antworten liefert, welche wiederum zur Interpretation durch das Large Language Model verwenden können.
- Für die Suche haben wir eine vektorbasierte Suche, welche präzisere Resultate liefert, verwendet. Ein schöner Nebeneffekt dieser Lösung ist der, dass die Abfragen auch toleranter auf Schreibfehler oder falsche Formulierungen der Fragen reagieren.
- Wir haben das Prompt-Engineering komplett überarbeitet. Ein Prompt ist eine Anweisung an ein Sprachmodell (LLM), um eine Antwort zu generieren. Ein gut formulierter Prompt sollte eine korrekte, angemessene und prägnante Antwort liefern. Die Qualität des Prompts beeinflusst die Qualität der Antwort des LLMs in hohem Masse.
- Innerhalb der Fragestellungen, werden sehr viele Synonyme verwendet, welche so aber in den verwendeten Daten nicht zu finden sind. Die Synonyme haben wir so eingebaut, dass diese dem LLM während dem Dialog mitgeteilt werden.
In einem zweiten Workshop zeigte sich, dass diese Anpassungen die Qualität der Antworten massiv verbesserten. Von den ursprünglich 11 Fragen konnten 10 korrekt beantwortet werden.
Das Fazit
Die hohen Erwartungen an eine KI-Lösung, die lokale Dokumente verwendet, wurden erfüllt. Das Wissen der Mitarbeitenden, das nicht dokumentiert ist, kann selbstverständlich nicht genutzt werden, was die Bedeutung vollständiger und umfassender Dokumentationen unterstreicht. Als Datenquellen kommen Dokumente aller Art, Datenbanken oder andere Textdateien infrage (Bsp. Wiki). Generell kann festgehalten werden, dass strukturierte Daten i.d.R. bessere Ergebnisse liefern. Im Zentrum einer Lösung steht immer eine Suche. Je besser die Resultate dieser Suche, desto besser die Beantwortung der Frage. Welche Art von Suche, ob textbasiert oder vektorbasiert, verwendet werden sollte, muss im Rahmen des PoC entschieden werden.
Die Einführung einer solchen Lösung erleichtert auch die Einarbeitung neuer Mitarbeitender und verbessert die Effizienz. Die Angst, dass Stellen abgebaut werden könnten, nur weil eine KI-basierende Lösung eingeführt wird, ist unbegründet.
Das Einführen einer generalisierten Out-of-the-Box-Lösung, welche alle möglichen Use Cases in einem Unternehmen beinhaltet, macht unserer Meinung nach keinen Sinn. Besser ist es, die wichtigsten Use Cases in einem ersten Schritt mithilfe eines Proof of Concept zu validieren. Entspricht das Resultat wirklich dem erwünschten Mehrwert für die Mitarbeitenden?
Wir sind von den Möglichkeiten von Azure OpenAI im Rahmen überzeugt. Gerne beraten und unterstützten wir Unternehmen bei der Evaluation der neuen Möglichkeiten und empfehlen die Umsetzung des KI Jumpstart Angebots von GARAIO.

